
こんな悩みにお答えします。
1. Aidemy
・・・AIエンジニアとしてのスキルを身に付けたい。その延長で就職、転職できたら嬉しい方におすすめ。
2.侍エンジニア塾
・・・基礎力と即戦力を身に付けられる、満足度No.1スクール
3. TechAcademy
・・・副業に向けてスキルアップしたい。フリーランスなどを目指している方向け。
4. AIジョブカレッジ
・・・コスパ良く、質の高い講座を受けたい方におすすめ。
本記事の信頼性
現在はデータサイエンティストとして大企業で活動しています。
1. 結論:
機械学習やデータ分析を行う際には、データの基礎集計を行う必要があります。
しかし、基礎集計も簡単ではありません。
- データ数
- 欠損値
- 特徴量分布
- カラム間の相関
などなど、複数の処理が必要になります。
そこで、pandas-profilingです。
pandas-profilingを用いることで、上のようなGIFをたった数行、数分で実装することができます。
2. 環境
以降、実際にコーディングしていく上で、実行環境を記載いたします。
- Python:3.6.4
- pandas_profiling:3.0.0

3. 概要

pandas-profilingは、Pandasデータフレームのプロファイリングレポートを作成するライブラリです。
a. インストール方法
pandas-profilingはpipにてインストールすることができます。
$$pip install pandas-profilingpython環境の構築には以下の記事をご覧ください。
>>【Python】Windows10へのインストール方法を解説(スクリーンショットあり)
>>【Python】【初心者必見】仮想環境の構築~venvの設定方法~
b. レポート項目
レポートに含まれる項目は以下のとおりです。
■レポート項目
- Overview
- Variables
- Interactions
- Correlations
- Missing values
- Sample
- Duplicate rows
それぞれ見ていきましょう。
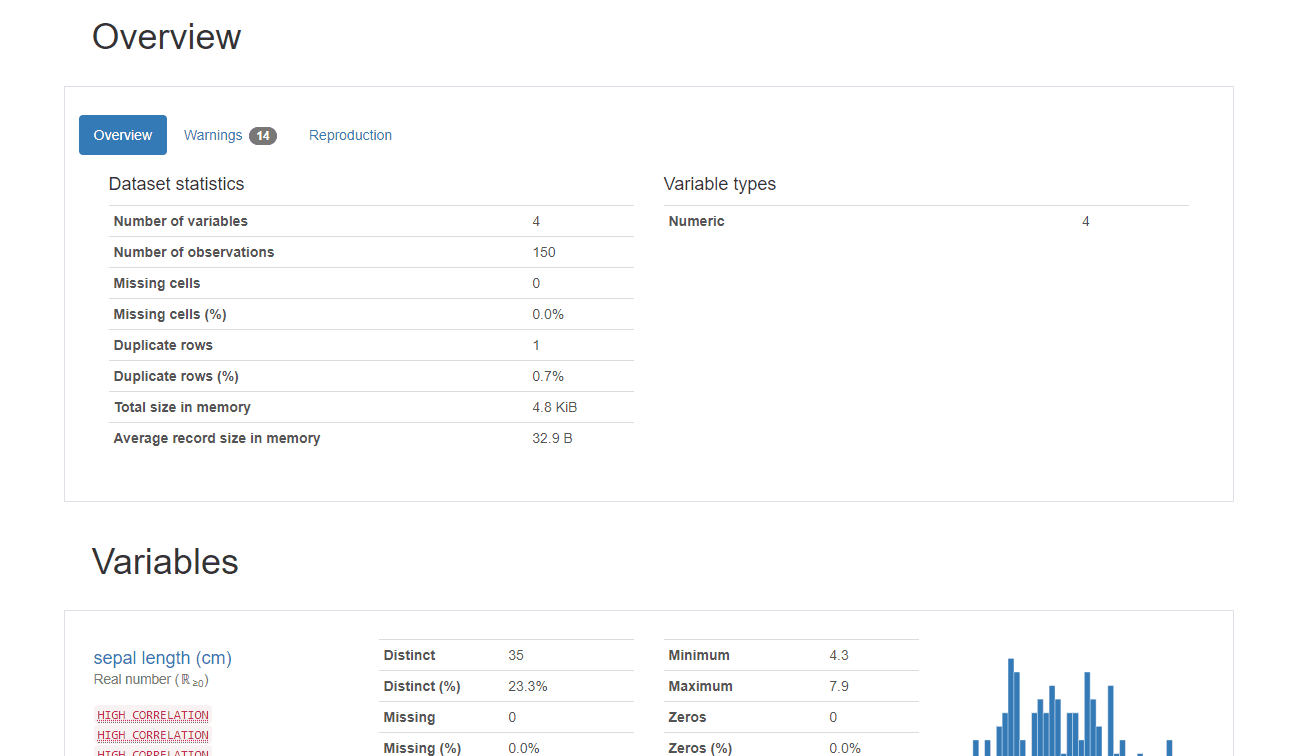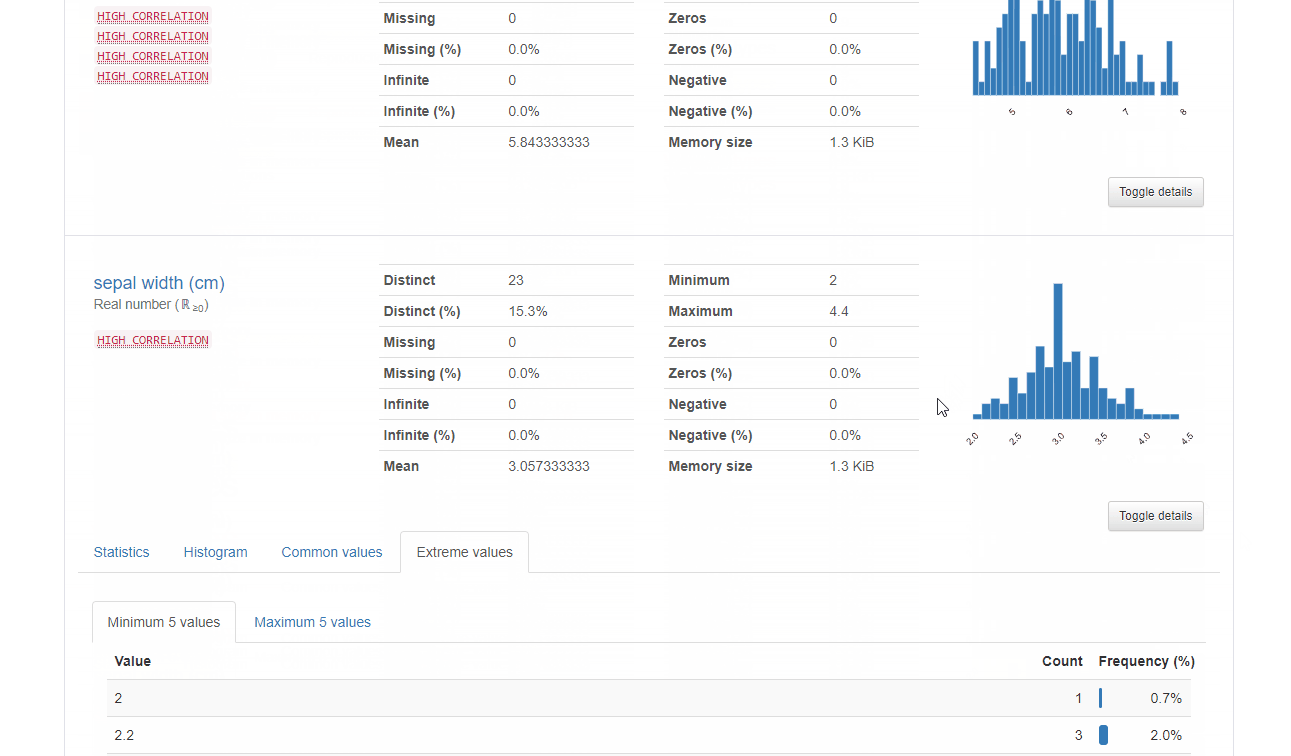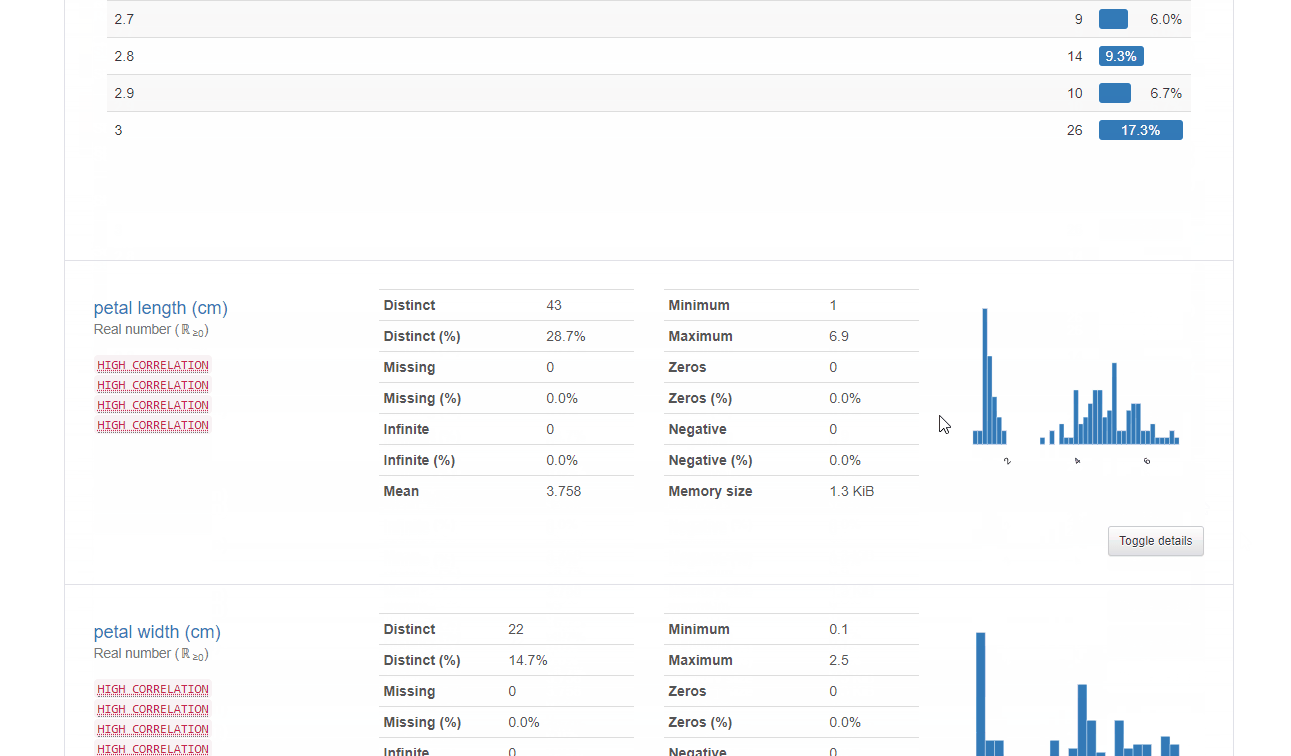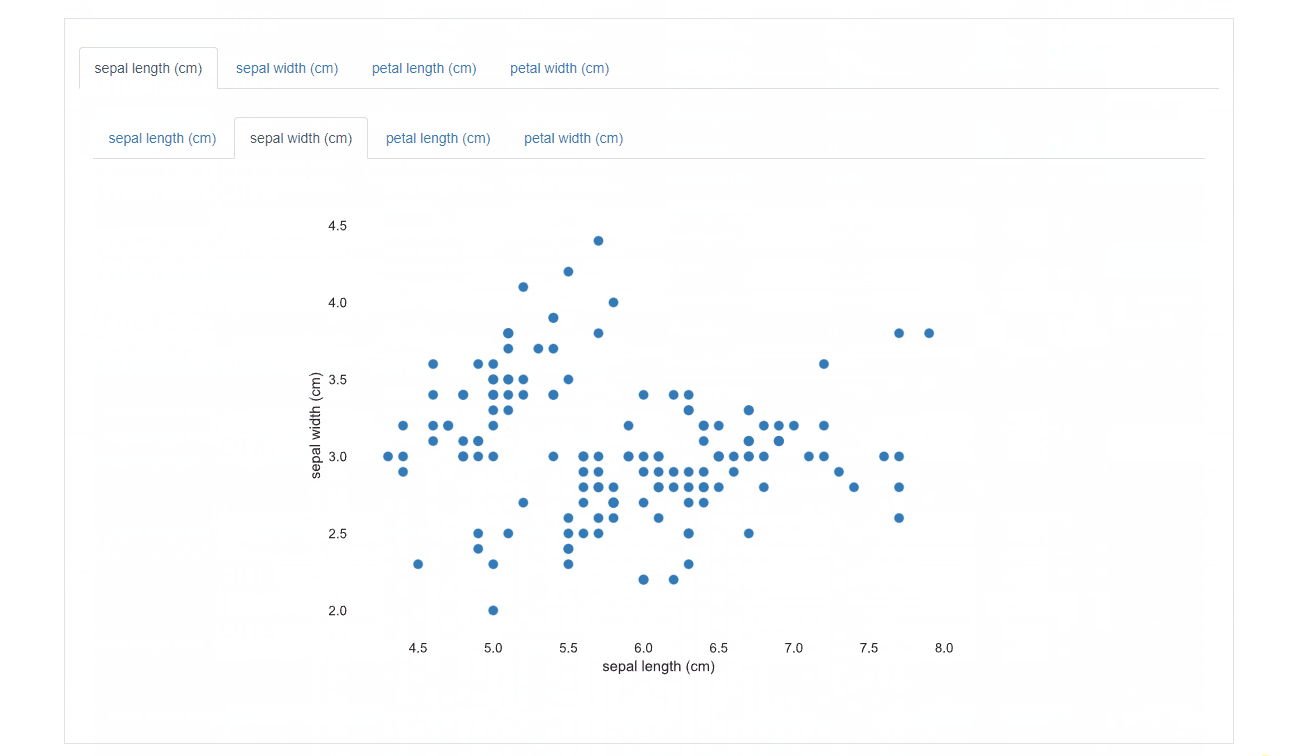
b-1. Overview
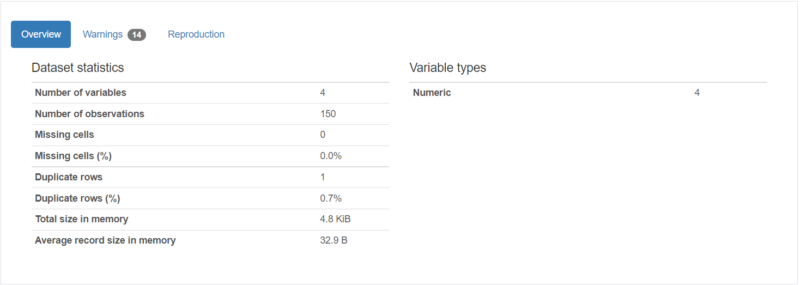
| 項目 | 概要 |
| Overview | データ数や特徴量の数などデータ概要 |
| Warnings | データ分析に関わる情報の提示(相関性の高い項目の明示など) |
| Reproduction | レポート作成に要した時間など |
b-2. Variables
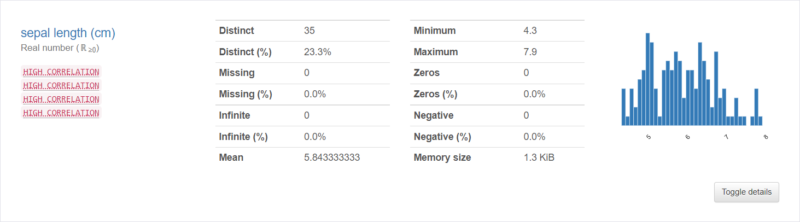
データ数や欠損値などを知ることができる上に、右下のToggle detailsを押下すると以下4種の情報も閲覧可能です。
| 項目 | 概要 |
| Statistics | 分位数と記述統計 |
| Histogram | データのヒストグラム |
| Common values | 共通値の頻度 |
| Extreme values | 最大・最小値 |
カテゴリカル変数の場合、表示形式が異なります。実際にデータを入力して確認してみましょう。
b-3. Interactions
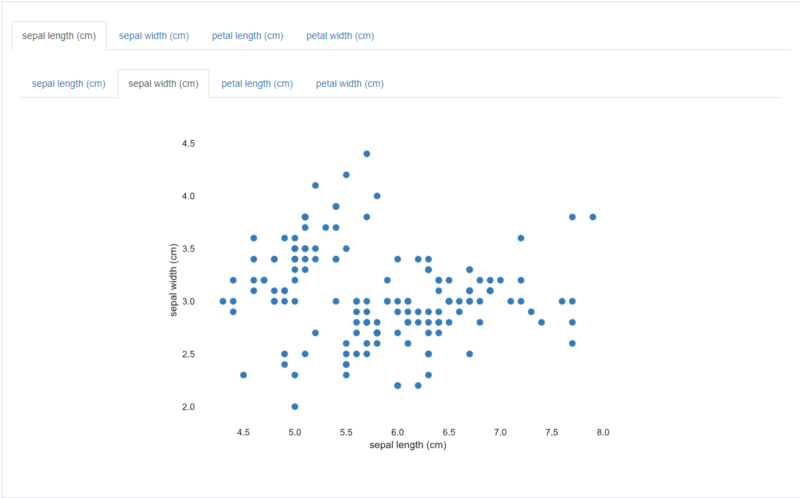
Interactionsでは、特徴量同士の関係性を視覚的に確認することができます。上部のタブで特徴量を選択することが可能です。
b-4. Correlations
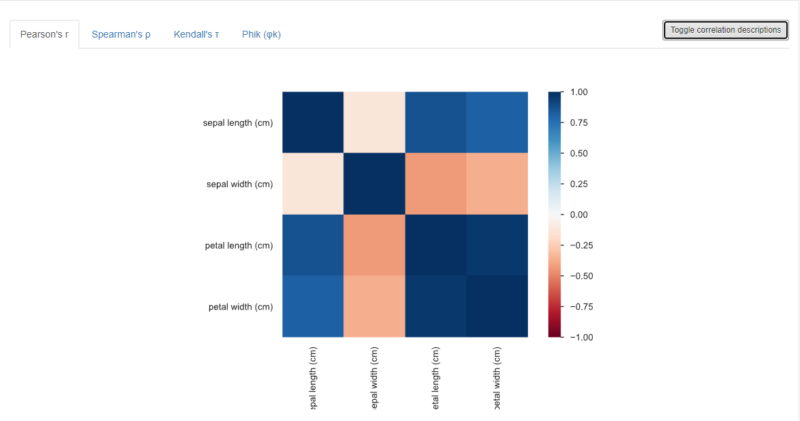
Correlationsは特徴量間の相関関係を表します。算出方法によって以下5指標を切り替えることが可能です。
| 項目 | 対象 | 概要 |
| Pearson’s r | 数値変数 | ピアソンの相関係数 |
| Spearman’s ρ | 数値変数 | スピアマンの相関係数 |
| Kendall’s τ | 数値変数 | ケンドールの相関係数 |
| Cramer’s V(φc) | カテゴリカル変数 | クラメールの連関係数 |
| Phik (φk) | 数値、カテゴリカル変数 | Phikの相関係数 |
上図では、4指標分しか記載されておりませんが、例に挙げたデータにカテゴリカル変数が含まれていないため、クラメールの連関係数が出力されていません。
b-5. Missing values
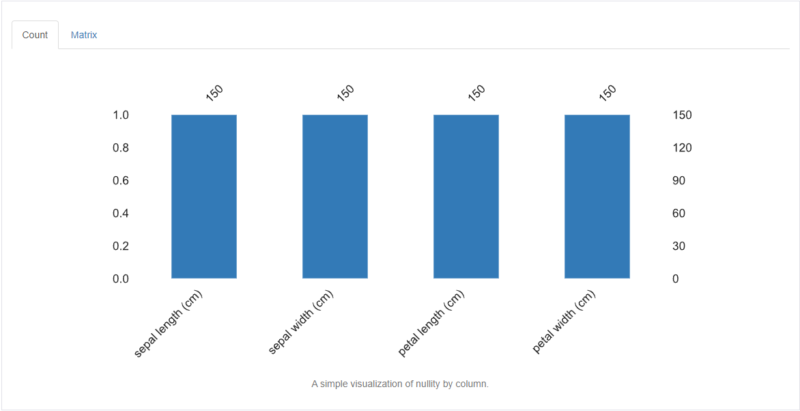
Missing valuesは欠損値を表します。上図は欠損値がないケースですが、Countタブでは欠損値が含まれている場合棒グラフが短くなります。
その他以下項目が表示されます(上図には欠損値が含まれていないため、CountとMatrixのみ確認することができます)。
| 項目 | 概要 |
| Matrix | データ密度(欠損値を含む場合空白が多くなる) |
| Heatmap | 欠損値を含む特徴量間の相関 |
| Dendrogram | 欠損値を含む特徴量との相関を表す樹形図 |
b-6. Sample
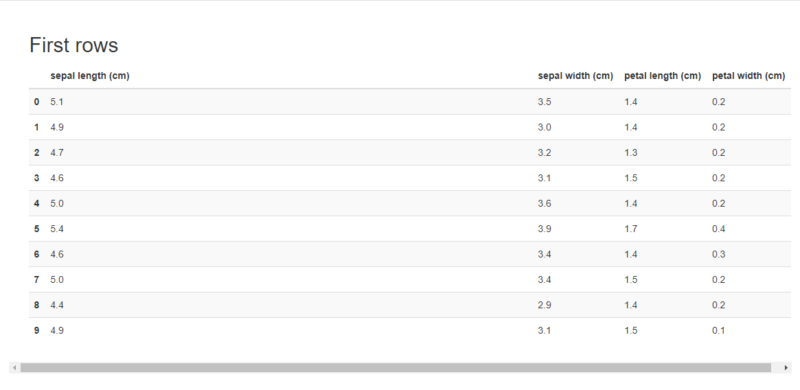
Sampleではデータの最初(First rows)と最後(Last rows)の10件を表示します。
b-7. Duplicate rows

Duplicate rowsは、重複しているデータを表します。全く同じ特徴量を持ったレコードがある場合に表示されます。
4.

ここから実際に
a. データセット
扱うデータとしては、Scikit-learnに用意されているデータセットIrisを採用しました。主に機械学習のデータとして用いられています。
| データ数 | 150 | |
| 特徴量 | 4 |
b. 実行の流れ
実行の流れは以下のとおりです。
- データの読み込み
- レポートの作成
- レポートの保存
1. データの読み込みでは、分析したいデータをPandasに変換します。
そして、2. レポートの作成で
それぞれたった1,2行程度で実装できるため、簡単にデータのプロファイリングレポートを作成することができます。
c. サンプルコード
import pandas as pd
import pandas_profiling as pdp
from sklearn.datasets import load_iris
#1. データの読み込み
iris_dataset = load_iris()
iris_dataframe = pd.DataFrame(data=iris_dataset.data, columns=iris_dataset.feature_names)
#2. レポートの作成
profile = pdp.ProfileReport(iris_dataframe)
#3. レポートの保存
profile.to_file("./data/iris.html") #ファイル名は適宜変更くださいd. 実行例
出力されたファイルがこちらです。
htmlとして保存され、簡単に結果を確認することができます。
5. まとめ

今回は、
機械学習やデータ分析においてデータの基礎集計は必須です。しかし、毎回手動で実行していては時間がかかってしまいます。
pandas-profilingを用いれば、たった数行でビジュアル的にも見やすいプロファイリングレポートを作成することができます。
これは、あなたのデータ操作を助けてくれること間違いなしです。時間を効率化するための最適解になり得ると思いますのでぜひ試してみてください。
・【株式投資】Pythonでスクリーニングする方法
・【Python】【株式投資】TA-Libによるテクニカル指標算出方法(移動平均、ボリンジャーバンド、MACD、RSI)
・【初心者向け】20分でできる!Pythonで銘柄スクリーニング結果をスマホへ通知する方法
・【Python】銘柄スクリーニング結果を定期的に通知する方法(無料)【30分でできる!】
本ブログでは、株式やプログラミングに関する記事を投稿しています。
プログラミング(Python)を学びたい方におすすめの書籍やプログラミングスクール、おすすめの学習方法などをご紹介しておりますのでぜひご覧ください。

は、プログラミングスクールという方法がおすすめです。
私の一押しは『TechAcademy』です。
質問することですぐに分からないところをクリアにできますし、進捗をサポートしてくれるため確実に成長することができます。
無料相談を実施しているため、まずは話を聞いてあなたのスタイルに合っているかどうか確認してみるのが良いと思います。



コメント